WHAT WE DO
CNN and LLM inference accelerators, from FPGA to ASIC.
SpiceEngine provides end-to-end design and implementation for dedicated AI accelerators. Our staged strategy starts with FPGA validation, moves to IP-core standardization, then transitions to ASIC.
Strengths
Staged Strategy
FPGA → IP core → ASIC
Value Indicators
1 ms recognition / under 5 W
Coverage
From edge to cloud
CNN Inference Accelerator
An accelerator stating up to 21x CNN inference performance versus Jetson baselines. The implementation targets low-latency, low-power computer vision workloads.
- High-speed execution with dataflow optimization
- Workload-specific optimization of bandwidth and memory
- Single design philosophy from FPGA implementation to ASIC deployment
LLM Inference Accelerator
Dedicated hardware for efficient LLM inference. The architecture is designed to reduce system overhead and provide practical throughput across deployment environments.
- Workload-aware implementation for model and compute characteristics
- Target deployment from data center to edge
- Evaluation and rollout aligned with a staged development model
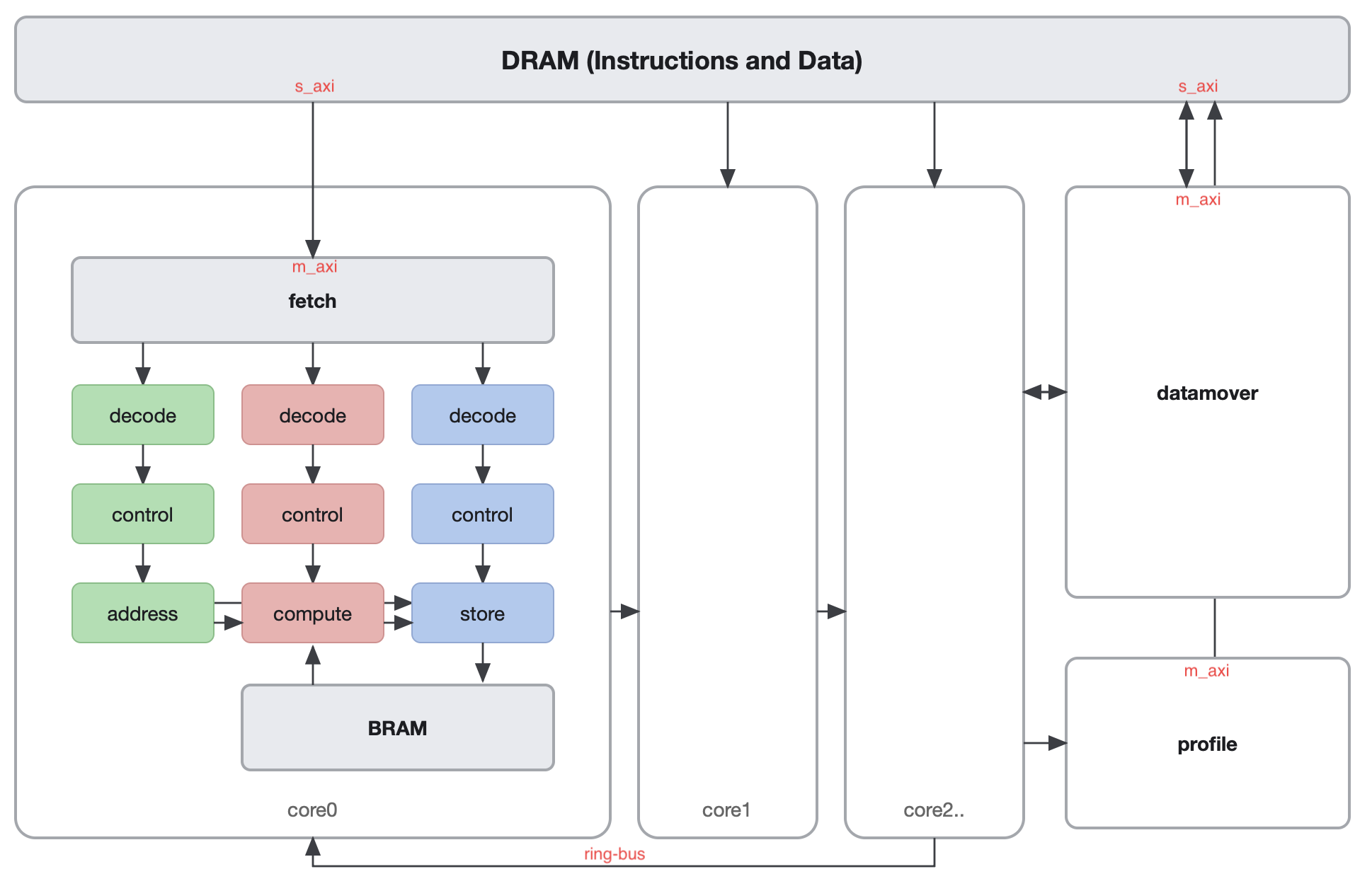
Technology
We combine dataflow architecture with dedicated hardware design to minimize CPU/GPU overhead. Wasabi2.0 is introduced as an integration of model compression, multicore architecture, and 8-bit quantization.
Use Cases / Applications
- Edge AI inference that requires low latency
- Power-sensitive embedded vision processing
- Unified operation from data center to edge